Automating DS Workflows with Multi‑Agent AI
Automating Kaggle Exploration with Multi‑Agent AI
Gen AI Intensive Capstone 2025 Q1
TL;DR
- Two‑agent pipeline (Research & Data Scientist) built with LangGraph + ReAct.
- Agents autonomously:
- mine domain knowledge & prior solutions,
- run EDA / feature ideation,
- recommend baseline models + CV strategy.
- Relies on Gen AI capabilities: function calling, structured Output, grounding, few‑shot prompting, agent orchestration.
- On classic Kaggle comps we already match ≈ 60‑80 % of top‑feature sets—within minutes, not days.
- Notebook, code, and video demo links at the end.
1 Why I Built This
Every data scientist spends days researching domain specific context, going through and anlyzing the data for the modelling task at hand before they end up with a base-line model. I wondered:
Can a swarm of LLM‑powered agents compress that busy‑work into a 5‑minute autopilot?
Enter the AI Data Scientist Helper. Its mission: hand the human a ready‑made “plan of attack” so we can dive straight into creative modeling, not clerical spelunking.
2 System Overview
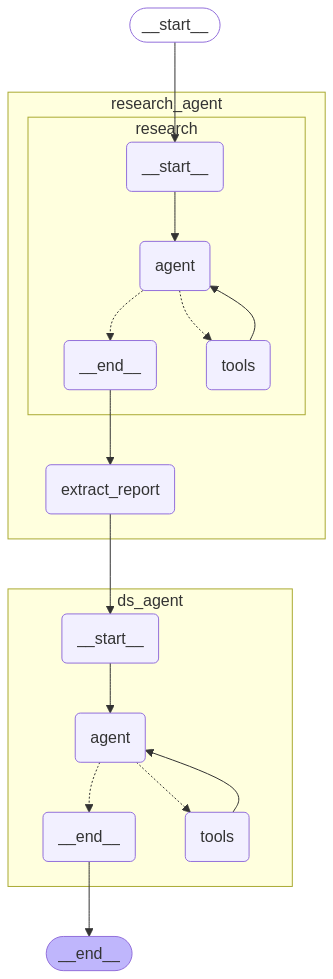
- Research Agent
- Scrapes papers, blogs, forum threads, retrieves similar competitions, and compiles a JSON research digest.
- Data Scientist Agent
- Pulls raw CSV via Kaggle API, runs EDA, proposes engineered features, selects baseline models & CV splits.
Both agents follow ReAct (Think → Tool → Observe → Repeat → Answer), implemented as LangGraph nodes with shared state.
3 Gen AI Superpowers Used
| Capability | Where It Appears |
|---|---|
| Structured JSON output | Research report schema & DS‑agent plan |
| Few‑shot prompting | Bootstraps reasoning steps and code style |
| Function calling | tavily_search(), execute_python_code() |
| Grounding | Adds web citations to every extracted fact |
| Agents (LangGraph) | Orchestrates multi‑step, multi‑tool workflows |
4 Diving into the Code 🔍
4.1 Minimal State
First we need to define the state for the agent’s graph. The state will contain inputs to the agent, intermediate state objects for communication between steps and agents, and output of the graph.
Inputs:
- competition_description
- data_description
- data_file_paths: a mapping of train/test data file paths
Intermediates:
- remaining_steps
- research_report: container for the research report
- python_state: agent’s python workspace state
from langgraph.graph import MessagesState
class AgentState(MessagesState):
"""State for the agent graph."""
remaining_steps: int
competition_description: str
data_description: str
data_file_paths: dict[str, str]
research_report: str
python_state: dict[str, Any]
4.2 Research Agent
Let’s first develope the research agent. We need to instruct the agent with clear objectives and a workflow to follow. We will do this by constructing a comprehensive and clear system prompt.
System Prompt
system_prompt_text = """
You are the Researcher Agent in a multi-agent system designed to support data scientists tackling predictive modeling tasks, such as those found in Kaggle competitions. Your primary responsibility is to perform deep domain and context research to generate a comprehensive technical report that informs downstream feature engineering and modeling efforts.
---
🎯 Objective:
Understand the business and modeling goals of the competition, identify domain-specific nuances, gather relevant contextual information, and surface structured insights that can shape hypotheses for feature creation and model selection.
---
🧾 Input:
A Kaggle competition description, which includes the modeling objective, data overview, and evaluation metric(s).
---
🔍 Research Workflow:
1. Parse and Understand the Objective
- Clarify the prediction task (classification, regression, ranking, etc.)
- Identify target variable(s), key entities, and evaluation metric(s)
- Understand the stakes or implications of the prediction
2. Domain-Level & Contextual Research
- What domain does this task belong to (e.g., healthcare, logistics, space travel)?
- What are common challenges or modeling pitfalls in this domain?
- What does success look like in similar real-world tasks?
3. Data Interpretation & External Enrichment
- Identify real-world meanings of the features
- Research how each feature might relate to the target
- Suggest any external datasets or public sources that could enrich understanding
4. Hypothesis Generation
- Based on research, suggest plausible drivers or causal mechanisms behind the target
- Surface any known correlations, failure scenarios, or interventions
5. Metric Implications
- Analyze the implications of the evaluation metric
- Recommend strategies that optimize for that metric (e.g., for LogLoss: calibrate probabilities)
---
📘 Deliverables:
Produce a structured research report including:
- Competition Summary (objective, target, metric, challenge type)
- Domain Understanding (core concepts, known challenges, useful priors)
- Feature Interpretations (intuition behind key fields)
- Hypotheses About Drivers (potential causal or predictive relationships)
- External Data Sources or Articles
- Strategic Suggestions for Modeling or EDA
- Annotated Bibliography (sources used for research)
---
📌 Guidelines:
- Prioritize authoritative sources: academic papers, reputable blogs, domain-specific articles, and public datasets
- Include links, diagrams, or examples to support findings
- Highlight uncertainties or assumptions where applicable
- Focus on relevance to predictive modeling—not general knowledge
- Be concise but insightful
---
# Competition Description
{competition_description}
# Data Description
{data_description}
"""
system_prompt = ChatPromptTemplate(
[
("system", system_prompt_text),
("placeholder", "{messages}"),
]
)
Agent
Create a tool calling ReAct agent using gemini-2.0-flash as the LLM. The Agent will have access to a tavily_search tool which enables it to perfrom dynamic web searches for its research.
def get_researcher() -> CompiledGraph:
search = TavilySearch()
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
agent = create_react_agent(
model=llm,
tools=[search],
prompt=system_prompt,
state_schema=AgentState,
name="researcher",
)
return agent
Next, define a node to extract the final report from the list of messages and update the research_report state variable:
def extract_report(state: AgentState):
ai_message = cast("AIMessage", state["messages"][-1])
return {"research_report": ai_message.content}
Finally, put these 2 nodes together to define the Research Agent’s graph:
from langgraph.graph import StateGraph
workflow = StateGraph(AgentState)
# add nodes and edges here
workflow.add_node("research", get_researcher()) # Note research node is technically a subgraph ReAct Agent
workflow.add_node("extract_report", extract_report)
workflow.set_entry_point("research")
workflow.add_edge("research", "extract_report")
workflow.set_finish_point("extract_report")
research_agent = workflow.compile()
4.3 Data Scientist Agent
Next, lets work on the data scientist agent. We will instuct the agent to act as an expert data scientist and help us with EDA and modeling tasks.
System Prompt
system_prompt_text = """
You are **Data‑Scientist Helper Agent**—an autonomous Python‑writing assistant that helps a human data‑scientist prepare for a Kaggle‑style competition.
### Inputs you will always receive
* **competition_description** – plain‑text overview of the challenge.
* **data_description** – schema, file names, column meanings, and any quirks.
* **research_report** – a domain‑specific report compiled by a separate Researcher Agent.
It may contain literature findings, feature ideas, industry best practices, failure modes, or suggested modeling approaches.
**Do not perform additional web research; rely on this report.**
### Mission
1. **Context Synthesis**
• Read all inputs. Extract: prediction target, constraints, metric, and standout insights from `research_report` (e.g., promising features, known data issues, domain rules).
• Summarize these in a short Markdown section **before** coding.
2. **Exploratory Data Analysis (EDA)**
• Load data (use only provided paths or helper functions).
• Produce concise EDA: shapes, missing patterns, basic stats, correlations, and domain‑specific checks inspired by `research_report`.
• Visualize with **Plotly**; narrate with `IPython.display.Markdown`; Use `IPython.display.display` instead of print.
3. **Feature Engineering & Baseline Modeling**
• Draft a **Feature Plan** that blends raw columns with transformations explicitly recommended—or implied—by `research_report`.
• Implement at least one clean, reproducible **baseline model** appropriate for the metric.
• Output validation scores and quick interpretation.
4. **Deliverables**
• A single Markdown **Research Report** containing
– Problem understanding & key research takeaways
– EDA highlights (figures already displayed)
– Final feature list (bullet list)
– Baseline model results & commentary
– Next‑step recommendations (hyper‑params to tune, alt. models, further features)
---
# Competition Description
{competition_description}
# Data Description
{data_description}
# Data File Paths
{data_file_paths}
# Research Report
{research_report}
"""
system_prompt = ChatPromptTemplate(
[
("system", system_prompt_text),
("placeholder", "{messages}"),
]
)
Code Execution Tool
The agent has access to a tool that allows it to execute Python code as part of its workflow. This is a basic implementation of that tool, featuring minimal safeguards and the ability to cache local variables between rounds of code execution. This enables the agent to sequentially build on its analysis in a stateful manner. 🧠⚙️
⚠️ Warning:
This implementation is not secure for production use. We need to implement robust sandboxing to ensure safe code execution—otherwise, the agent might gain access to your bank accounts, order a fleet of GPUs, and begin cloning itself to take over the world. Proceed with extreme caution. 😅🤖🛑
@tool
def execute_python_code(
code: str,
output_key: str,
state: Annotated[dict[str, Any], InjectedState],
tool_call_id: Annotated[str, InjectedToolCallId],
) -> Command:
"""
Runs Python in a shared, state‑preserving kernel.
Parameters
----------
code : str
The Python code snippet to be executed
output_key : str
The key that will be used to extract the output from local variables after code execution
"""
# 1) Pull the previous workspace (or start fresh)
workspace: dict[str, Any] = state.get("python_state", {}).copy()
# 2) Prepare sandboxed namespaces
globals_ns: dict[str, Any] = {}
locals_ns: dict[str, Any] = {**workspace}
# 3) Run the user‑supplied code
exec(code, globals_ns, locals_ns)
# 4) Pickle everything that isn’t a dunder so deepcopy will never complain
persisted: dict[str, bytes] = {}
skipped: list[str] = []
for k, v in locals_ns.items():
if k.startswith("__"):
continue
try:
persisted[k] = cloudpickle.dumps(v)
except Exception:
skipped.append(k)
# Use the custom serializer for JSON serialization
result_json = ""
if output_key:
output = {output_key: locals_ns.get(output_key)}
try:
result_json = json.dumps(output, default=json_serializer)
except (TypeError, ValueError, json.JSONDecodeError) as e:
print("Error serializing output: %s. Using string representation instead.", str(e))
result_json = json.dumps({output_key: str(output[output_key])})
# 5) Push the updated workspace back into the overall agent state
return Command(
update={
"python_state": persisted,
"messages": [
ToolMessage(
f"Successfully executed code snippet.\nResult: {result_json}",
tool_call_id=tool_call_id,
)
],
},
)
Agent
Finally, we can define the react agent using the LLM, system_primp, and code execution tool.
def get_ds_agent() -> CompiledGraph:
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
agent = create_react_agent(
model=llm,
tools=[execute_python_code],
prompt=system_prompt,
state_schema=AgentState,
name="data_scientist",
)
return agent
ds_agent = get_ds_agent()
4.4 Let Agents Communicate
We now have defined two agents: a researcher and a data scientist. All we need to do now is to connect the two agents together so we can have a full automated workflow going from research to EDA to modelling and evaluation.
workflow = StateGraph(AgentState)
# add nodes and edges here
workflow.add_node("research_agent", research_agent)
workflow.add_node("ds_agent", ds_agent)
workflow.set_entry_point("research_agent")
workflow.add_edge("research_agent", "ds_agent")
workflow.set_finish_point("ds_agent")
full_agent = workflow.compile()
5 Walk‑Through ✈️ Spaceship‑Titanic
We will use this kaggle competition to test the agent on.
Let’s run the agent:
# https://www.kaggle.com/competitions/spaceship-titanic/overview/description
competition_description = """
... include the desription here from the competition
"""
# https://www.kaggle.com/c/spaceship-titanic/data
data_description = """
...
"""
data_file_paths = {
"train": "/kaggle/input/spaceship-titanic/train.csv",
"test": "/kaggle/input/spaceship-titanic/test.csv"
}
payload = {
"competition_description": competition_description,
"data_description": data_description,
"data_file_paths": data_file_paths,
"messages": [("human", "help me with this kaggle competition")],
}
final_state = run_agent_stream(full_agent, payload)
First the agent will read through the competition and data descriptions and start planning it’s work:
Okay, I will help you with the Kaggle competition “Spaceship Titanic”. I will perform research to generate a comprehensive technical report that will inform downstream feature engineering and modeling efforts…
Then, it will use the search tool to do some research for us:

Then, it gives us a high level strategic suggestions for EDA and modeling:

After the research report is generated, we will pass it along to our expert DS agent who starts thinking through its analysis steps:

After a few steps of EDA here is the final code that the agent executed to train some baseline models and achivied a Validation Accuracy of ~78%!

Validation Accuracy: 0.7791834387579069
6 Evaluation Protocol
| Step | Detail |
|---|---|
| Benchmarks | Ten classic Kaggle comps (Titanic, House Prices, Santander…) |
| Ground Truth | Winning solution write‑ups & feature lists |
| Metrics | Feature Hit‑Rate, Model Class Match, CV Strategy Match |
| Current Score | TODO |
7 Limitations & Next Steps
| Pain Point | Planned Fix |
|---|---|
| Occasional research hallucinations | Add semantic re‑rank + citation verifier |
| Static two‑agent design | Experiment with a Supervisor Agent spawning dynamic toolchains |
| risky code execution tool | implement a more secure sand-boxing mechanism |
| improve long-term planning and code execution | summarize steps; include multimodality (analyzing graphs); |
8 Resources
| Link | Description |
|---|---|
| Notebook | interactive, executable version on Kaggle |
| Video Walkthrough | demo & walkthrough video on loom |
© 2025 Amir Sharifzad – feedback & PRs welcome!